
As programmers, the need for taking screenshots of web pages programmatically occurs in many situations. For example, when you write automation tests, you may want to take screenshots to compare the rendered web pages with the expected web pages. Or you might want to generate an image preview of the content of the dynamic web pages served by your application to post to social media. Another use case is web scraping, where you want to take screenshots of web pages from various websites.
In this tutorial, you'll learn how to take screenshots of web pages in Clojure using different methods:
- A Clojure WebDriver called Etaoin
- A Headless ChromeDriver called Puppeteer, wrapped by ClojureScript
- A service called Urlbox
Taking Screenshots with Etaoin
Etaoin implements the WebDriver protocol in pure Clojure. WebDriver is a remote control interface that enables introspection and control of browsers. Etaoin controls web browsers via their WebDrivers, and each browser has its own WebDriver implementation that must be installed and launched.
For this tutorial, you'll be using Chrome. You'll need to install ChromeDriver with the following command:
- macOS:
brew install chromedriver - Windows:
scoop install chromedriver
You launch the ChromeDriver, by executing the following command in your terminal:
chromedriver
Now, you create a Clojure project and add Etaoin to your project dependency list by putting the following into the :dependencies vector in your project.clj file:
[etaoin "0.4.6"]Or the following under :deps in your deps.edn file:
etaoin/etaoin {:mvn/version "0.4.6"}The code for taking a screenshot is straightforward. Here is how to take a screenshot of an article on TechCrunch:
(ns screenshots.demo
(:require [etaoin.api :as e]))
(def driver (e/chrome))
(e/go driver "https://techcrunch.com/2022/08/04/the-5-biggest-takeaways-from-teslas-cyber-roundup/")
(e/screenshot driver "etaoin-techcrunch.png")The screenshot looks like this:
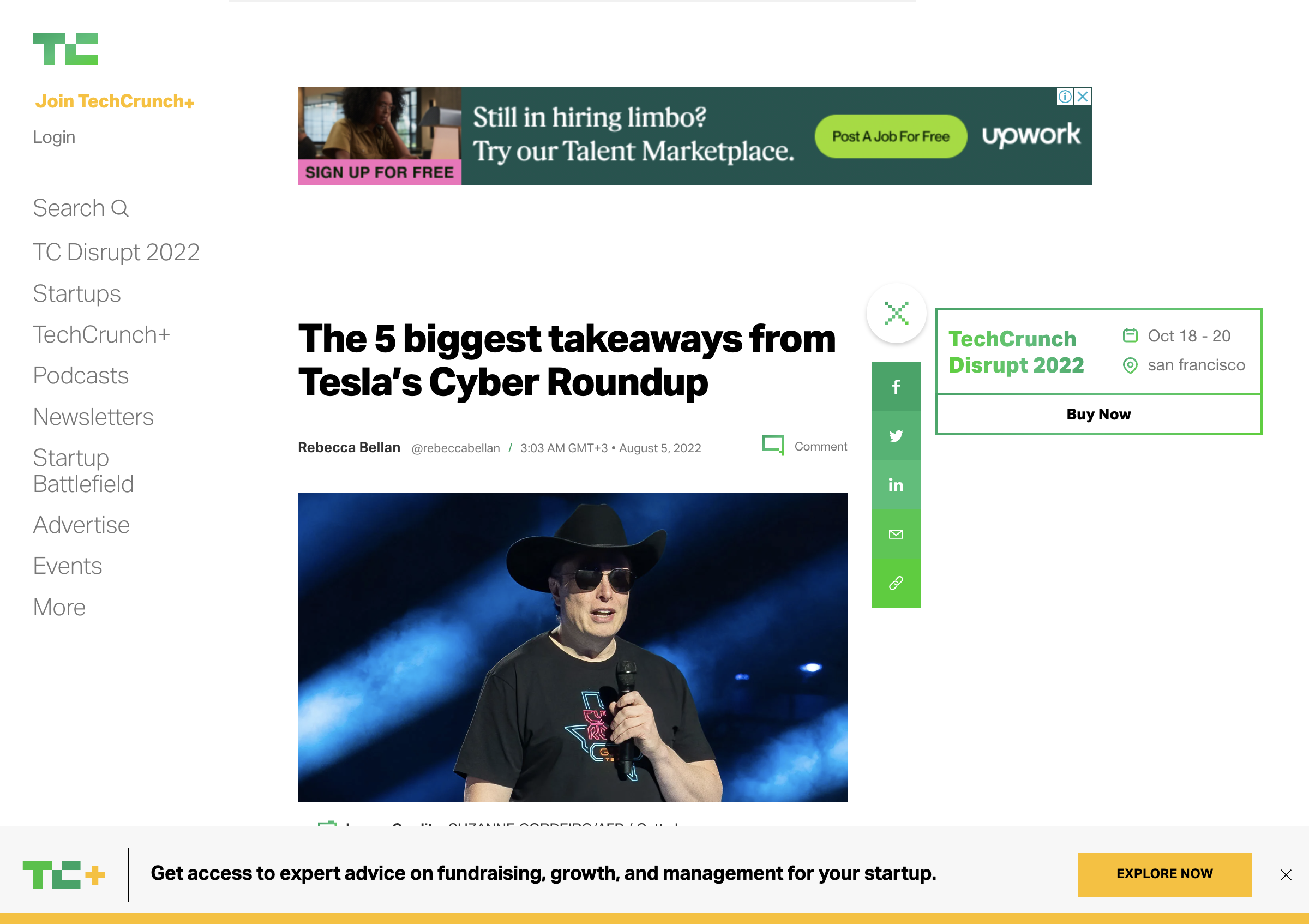
Etaoin provides many features to control the browser, such as waiting for an element to be present on the page, or controlling the viewport size. You can learn more about it in Etaoin user guide.
Taking full-page screenshots with Etaoin is possible, but because taking a full-page screenshot is not part of the WebDriver W3C screen capture standard, it requires browser-dependent custom code that is also browser dependent. For example, here is the code for taking a full-page screenshot with the Chrome browser:
(let [resp (e/execute {:driver driver
:method :get
:path [:session (:session driver) "screenshot" "full"]})
b64str (some-> resp :value)]
(with-open [out (io/output-stream "etaoin-techcrunch-full-page.png")]
(.write out ^bytes
(-> (Base64/getDecoder)
(.decode b64str)))))The benefits of Etaoin are that it is written in pure Clojure and that, while this example uses Chrome, Etaoin works with multiple browsers. This ability is particularly important in the context of automation tests, where you need to check how your application behaves with various browsers.
The main challenge with Etaoin is that you need to install and launch the browser manually. It is particularly challenging if you want to take screenshots in production or as part of your continuous integration flow.
Moreover, as you may have noticed in the TechCrunch homepage screenshot above, there's no ad-blocking ability, so advertisements appear in the screenshot.
In the next section, you'll explore a solution that avoids the need to launch the browser manually.
Taking Screenshots with Puppeteer
Puppeteer is a Node.js library that provides a high-level API to control Chrome over the DevTools Protocol, a protocol that allows for tools to instrument, inspect, debug, and profile Chrome.
You can easily use Puppeteer inside a ClojureScript program by using shadow-cljs as your build tool. With shadow-cljs, using npm modules works like a charm. The only thing you need to do is to create a ClojureScript project and add puppeteer to your dependencies in package.json, by executing:
npm add puppeteer
And here is the ClojureScript code for taking a screenshot of another article from TechCrunch:
(ns screenshot-demo.core
(:require ["puppeteer" :as p]))
(-> (p/launch)
(.then (fn [browser]
(.newPage browser)))
(.then (fn [page]
(-> (.goto page "https://techcrunch.com/2022/08/04/hbo-hbo-max-and-discovery-report-a-combined-total-of-92-1m-subscribers-plans-for-major-restructuring/")
(.then (fn [_]
(.screenshot page #js {:path "/tmp/puppeteer.png"})))
(.then #(println "Done!"))))))Puppeteer, being a JavaScript library, deals with promises, which is why the code is made of several (.then ...) expressions. If you're not already familiar with JavaScript, you may find it frustrating.
Here is the result:

With Puppeteer, taking a full-page screenshot is much simpler than with Etaoin. You need to add:fullPage true to the option map passed to (.screenshot ...):
(.screenshot page #js {:path "/tmp/puppeteer.png"
:fullPage true})Like Etaoin, Puppeteer provides many ways to control the browser, such as waiting for an element to be present on the page, or controlling the browser viewport. You can learn more about it in Puppeteer API reference.
The main benefit of Puppeteer is that it doesn't require installing and launching the browser manually. Puppeteer takes care of everything.
However, one of the major drawbacks of Puppeteer is that it offers limited ability to control the browser. There's no way to dismiss a cookies warning or bypass a CAPTCHA, for example.
Like Etaoin, Puppeteer requires managing a server. It is not as easy as it might sound. For example, a Puppeteer-based server on Heroku wasn't able to handle multiple requests in parallel and crashed, probably due to the process memory limitation on Heroku.
In the next section, you'll look at a solution that doesn't require managing a server.
Taking Screenshots with Urlbox
So far, you've seen how to take screenshots by using third-party libraries that allow you to control a web browser. The main challenge with this approach is that you have to run a headless web browser as part of your production system.
A simpler approach is to use an external service like Urlbox.
Urlbox is a service that provides a simple and flexible screenshot API, and lets you avoid the need to manage and maintain your own server for taking screenshots. Moreover, Urlbox can block ads out of the box.
In order to use Urlbox, you need to create an account at Urlbox and retrieve your API token from it. Once you have an API token, taking a screenshot is as simple as accessing a URL.
The URL is made of:
- Urlbox API endpoint:
https://api.urlbox.io/v1/ - API token
- Desired image format (PNG, JPG, JPEG, AVIF, WebP, PDF, SVG, HTML)
- Query parameters with the encoded URL of the web page that you want to take a screenshot of
For instance, you can take a PNG screenshot of https://techcrunch.com/2022/08/04/hbo-hbo-max-and-discovery-report-a-combined-total-of-92-1m-subscribers-plans-for-major-restructuring/ by accessing https://api.urlbox.io/v1/api-token/png?url=https%3A%2F%2Ftechcrunch.com%2F2022%2F08%2F04%2Fhbo-hbo-max-and-discovery-report-a-combined-total-of-92-1m-subscribers-plans-for-major-restructuring%2F.
Here is the result:

In addition, the Urlbox API provides several options to configure the screenshot. For instance, in order to take a full-page screenshot, you can pass full_page=true as an additional query parameter.
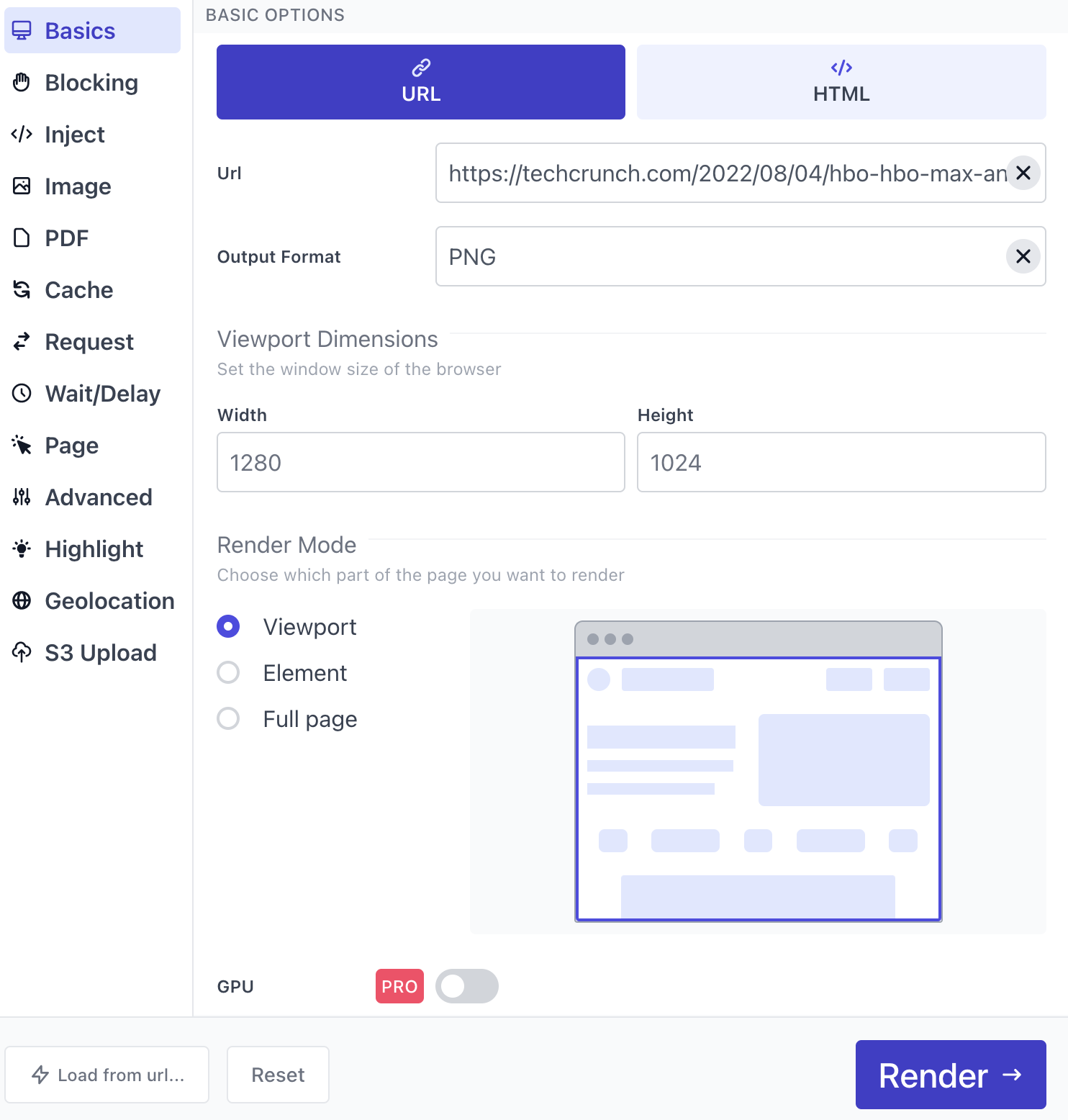
The full list of options is available at Urlbox options reference. You can interact and experiment with the various options at Urlbox online dashboard.
The dashboard looks like this:
Now, let's write a piece of Clojure code that:
- receives a map of options
- converts it to a Urlbox URL
- accesses the URL
- saves a file with the image
You can use Clojure libraries to save you time writing low-level code:
lambdaisland.urito convert maps to encoded URL parametershttp-clientto access Urlbox endpoint
(ns screenshot-demo.urlbox
(:require
[clj-http.client :as http]
[lambdaisland.uri :refer [map->query-string]]
[clojure.java.io :as io]))This is a function that receives a token, an image format, and an options map, and returns the corresponding Urlbox URL:
(defn urlbox-url [token image-format options]
(str "https://api.urlbox.io/v1/"
token
"/"
image-format
"?"
(map->query-string options)))And here is a little utility function to save binary files:
(defn save-binary! [path content]
(with-open [w (io/output-stream path)]
(.write w content)))Now, let's take a screenshot of the article "Screenshot" on Wikipedia:
(def url "https://en.wikipedia.org/wiki/Screenshot")
(def token "<your-token>")
(->> (http/get (urlbox-url token "jpg" {:url url
:height 200})
{:as :byte-array :throw-exceptions false})
:body
(save-binary! "/tmp/screnshot.jpg"))Notice how easy it is to control the height of the browser viewport by setting :height 200 in the option map.
Here's the result:
The main benefit of Urlbox is that you don't have to deal at all with the management of a web service that runs the browser. Everything is taken care of by Urlbox. Urlbox can also block ads, bypass CAPTCHAs, simulate user interaction, and offers a wide array of options when it comes to controlling the look of the finished screenshot.
Wrapping Up
In this article, you've looked at multiple approaches to taking screenshots of web pages in Clojure and ClojureScript. Solutions like Etaoin and Puppeteer give you full control of the underlying web browser, but they require you to manage a web server, and offer limited control over what the final screenshot looks like.
A solution like Urlbox spares you from needing to manage a server and a browser in production. The only thing that you have to deal with is the generation of the URL programmatically, which is straightforward in a language like Clojure. All the complexity of the browser and server management in production is taken care of by the service, freeing you up to spend your time on your core business functions.
