
It can be useful to block image requests when using puppeteer for web scraping and other activities.
This can help speed up the page load time and reduce the amount of data that needs to be downloaded.
This is especially useful when using a proxy server to scrape pages, as it can reduce the amount of bandwidth used, and therefore reduce the overall cost of your proxy per page scraped.
Using request interception naïvely
The easiest way to block images with puppeteer is using the built in request interception feature.
Once request interception is turned on, every request will stall unless it's continued, responded or aborted.
Here's a naïve example of blocking image requests with puppeteer (don't use this in production!):
import puppeteer from "puppeteer";
const browser = await puppeteer.launch({
headless: false,
});
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on("request", (request) => {
if (request.resourceType() === "image") {
console.log("Blocking image request: " + request.url());
request.abort();
} else {
request.continue();
}
});
await page.goto("https://urlbox.com");
await page.setViewport({ width: 1280, height: 3000 });
await page.screenshot({ path: "./urlbox.png" });
await browser.close();When this script is run, the output on the command line will look similar to:
$ bun puppeteer-block-images.js
Blocking image request: data:image/svg+xml;charset=utf-8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 800 600'%3E%3Cfilter id='b' color-interpolation-filters='sRGB'%3E%3CfeGaussianBlur stdDeviation='20'/%3E%3CfeColorMatrix values='1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 100 -1' result='s'/%3E%3CfeFlood x='0' y='0' width='100%25' height='100%25'/%3E%3CfeComposite operator='out' in='s'/%3E%3CfeComposite in2='SourceGraphic'/%3E%3CfeGaussianBlur stdDeviation='20'/%3E%3C/filter%3E%3Cimage width='100%25' height='100%25' x='0' y='0' preserveAspectRatio='none' style='filter: url(#b);' href='/images/screenshots/stripe-desktop.jpg'/%3E%3C/svg%3E
Blocking image request: data:image/svg+xml;charset=utf-8,%3Csvg xmlns='http://www.w3.org/2000/svg' %3E%3Cfilter id='b' color-interpolation-filters='sRGB'%3E%3CfeGaussianBlur stdDeviation='20'/%3E%3CfeColorMatrix values='1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 100 -1' result='s'/%3E%3CfeFlood x='0' y='0' width='100%25' height='100%25'/%3E%3CfeComposite operator='out' in='s'/%3E%3CfeComposite in2='SourceGraphic'/%3E%3CfeGaussianBlur stdDeviation='20'/%3E%3C/filter%3E%3Cimage width='100%25' height='100%25' x='0' y='0' preserveAspectRatio='xMidYMid slice' style='filter: url(#b);' href='https://pbs.twimg.com/profile_images/1478327435041153034/gfkjGjQF_400x400.jpg'/%3E%3C/svg%3E
Blocking image request: https://urlbox.com/_next/image?url=https%3A%2F%2Fpbs.twimg.com%2Fprofile_images%2F1883092999%2FScreen_Shot_2012-03-09_at_1.12.00_PM_400x400.png&w=1920&q=75
...
This puppeteer script is blocking all image requests, including data:image/svg+xml images that are loaded via CSS. This will lead to a great saving in bandwidth.
Let's see the resulting screenshot to show the images that were blocked:
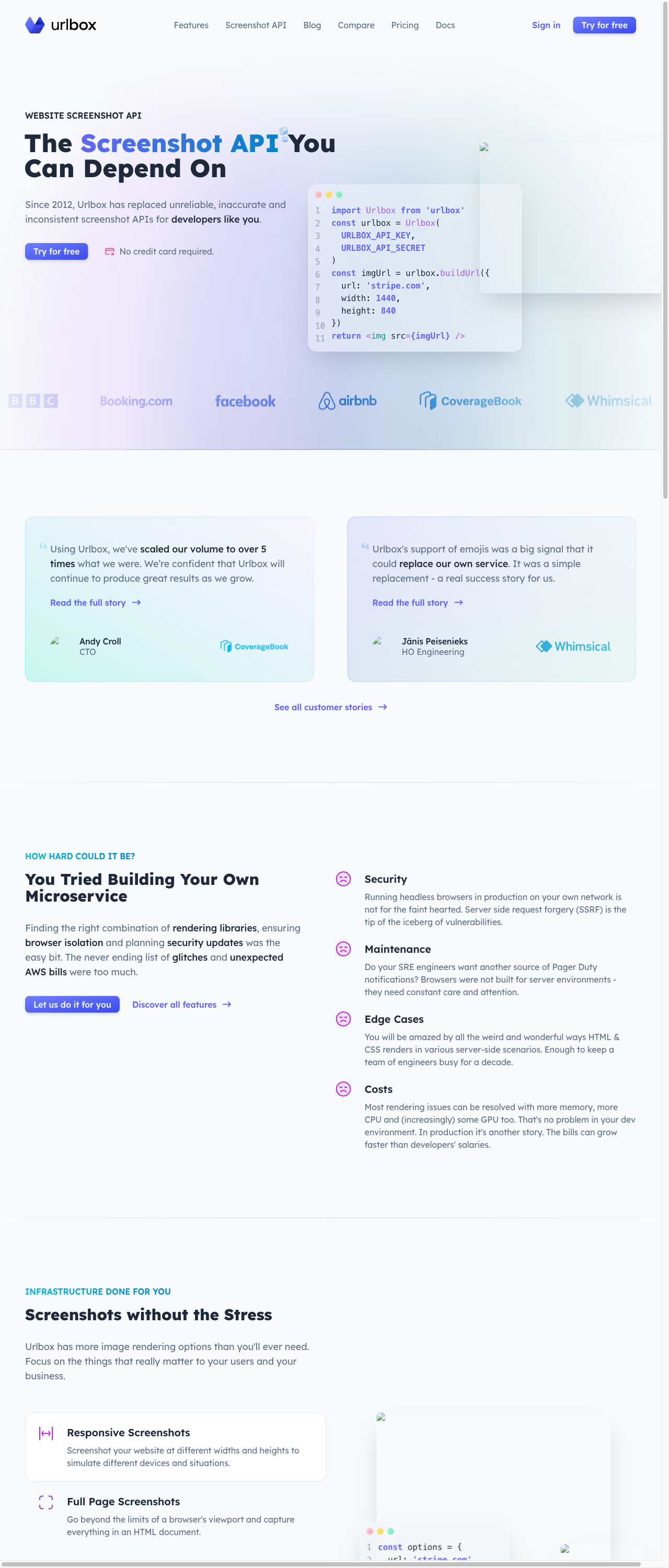
You'll notice that the images look broken because of the image requests being blocked.
However, the brand logos and some icons are still visible in the screenshot. This is because the brand logos are inline SVG embedded inside the HTML document, and not loaded via an image request.
The trouble with request interception
If you are using puppeteer to do web scraping, it is likely that you're also going to be using a third party package that also wants to intercept requests.
Examples of third party packages that hook into puppeteer to intercept requests are:
- adblockers, such as @cliqz/adblocker
- resource blockers, such as puppeteer-extra-plugin-block-resources
If you naïvely handle request interceptions like above whilst using third party libraries that also want to intercept requests, you will likely run into problems.
The main problem will be that puppeteer will raise a Request is already handled! exception if you try to continue, abort or respond to a request that has already been handled by another library.
Further problems could result in certain requests getting stalled, causing timeouts when navigating to certain URL's.
Being aware of multiple request interception handlers
These problems can be guarded against by always assuming that you are not the only one intercepting requests.
Let's rewrite the request interception handler above to be more robust:
page.on("request", (request) => {
if (request.isInterceptResolutionHandled()) {
return;
}
if (request.resourceType() === "image") {
console.log("Blocking image request: " + request.url());
request.abort();
} else {
request.continue();
}
});We added the request.isInterceptResolutionHandled() check to ensure that the request hasn't already been handled by another handler before we handle it.
This prevents us from receiving the Request is already handled! exception and shields us from other bugs.
Multiple async request interception handlers
Handlers can also be async, and the value of request.isInterceptResolutionHandled() is only safe to use in the same synchronous code block as where you call request.continue/abort/respond.
If you are awaiting an asyncronous operation as part of your request interception handler, you need to ensure that you always call request.isInterceptResolutionHandled() in the same synchronous context before going on to call abort/continue/respond.
Let's see an example of this:
page.setRequestInterception(true);
// first async handler
page.on('request', async (request) => {
// request hasn't been handled here so will continue..
if (request.isInterceptResolutionHandled()) return;
await sleep(5000);
// we need to check again here because the request
// might have been handled by the handler below while we were awaiting the sleep
if (request.isInterceptResolutionHandled()) return;
await request.continue();
});
// second async handler (this could be somewhere in a third party library)
page.on('request', async (request) => {
if (request.isInterceptResolutionHandled()) return;
await sleep(3000);
// once again we check here because the request
// may have been handled while we were awaiting the sleep
if (request.isInterceptResolutionHandled()) return;
await request.continue();
})
Using co-operative request intercept mode
Co-operative request interception is a way for multiple libraries to intercept requests in a way where they do not compete with each other and with your own puppeteer script.
Using co-operative request interception requires passing a priority into the request.abort, request.continue or request.respond methods as the second argument.
The default priority is 0, and the method that gets called with the highest priority wins.
However, if any one handler does not pass a priority into the abort/continue/respond methods, then it will prevail, so it's important to check the source code of any third party packages that are doing request interception to ensure they have been updated to use co-operative request interception before relying on it.
Here's an example of how co-operative request interception works:
page.setRequestInterception(true);
// first handler
page.on('request', (request) => {
if (request.isInterceptResolutionHandled()) return;
await request.continue({},1);
});
// second handler (this could be somewhere in a third party library)
page.on('request', (request) => {
if (request.isInterceptResolutionHandled()) return;
await request.abort({},2);
})In the above example, the second handler will always win, and the request will be aborted because abort's priority of 2 is greater than continue's priority of 1.
Using the chrome devtools protocol directly to block images with puppeteer
It's also possible to drop down a level of abstraction and use the underlying chrome devtools protocol (CDP) in order to start intercepting requests.
First, we need to get a handle to a CDP session and enable the Fetch domain. The fetch domain allows us to substitute the browser's network layer with our own custom code.
When enabling the fetch domain, we pass in a urlPattern which filters the requests that we want to intercept based on their URL. In our example, we want to intercept all requests, so we use the wildcard * as the urlPattern.
const client = await page.target().createCDPSession();
await client.send("Fetch.enable", {
//see: https://chromedevtools.github.io/devtools-protocol/tot/Fetch#type-RequestPattern
// handleAuthRequests: true,
patterns: [
{
urlPattern: "*",
requestStage: "Request",
},
],
});
Next we need to setup an event handler for the Fetch.requestPaused event.
This event gets fired when a request matching the urlPattern is received.
Within this event handler function, we run custom code to decide what to do with each individual request.
As this post is about blocking image requests, we'll check the resourceType of the request and if it's an Image, we can abort the request.
//see: https://chromedevtools.github.io/devtools-protocol/tot/Fetch#event-requestPaused
client.on("Fetch.requestPaused", async (event: any) => {
const {
request,
resourceType
} = event;
const { url, method } = request;
if(resourceType === "Image") {
console.log("Blocking image request: " + url);
await client.send("Fetch.failRequest", {
requestId,
errorReason: "BlockedByClient",
});
return;
}
await client.send("Fetch.continueRequest", {
requestId,
});
});
Running this will give us the same behaviour as the request interception examples above.
We could also check for other resource types here, such as fonts, scripts and stylesheets and decide to block those too, as this will save us extra bandwidth.
