
Knowing when a page has finished loading is a crucial first step to taking accurate website screenshots with puppeteer.
Taking a screenshot before the page has fully loaded will result in a bad screenshot where images are not loaded and styles have not been parsed and applied.
Waiting for too long after the page is loaded, means we are wasting unneccessary time and causing the screenshot request to take longer than is required.
Striking the right balance between the page being fully loaded and getting a quick screenshot is quite a challenge when it is applied generally to any website.
In general, there is no one size fits all solution, and usually different websites require different strategies.
Below we describe a few different strategies to determine when a page has fully loaded.
How to know when a Page is loaded in Puppeteer
Puppeteer gives us four events we can wait on to detect when a page has loaded. We can access these options via the waitUntil option that we pass to page.goto. We could also use a call to page.waitForNavigation and wait for these events to fire.
waitUntil: domcontentloaded
The domcontentloaded option will fire the earliest, and is the equivalent of waiting for the DOMContentLoaded event on the document:
document.addEventListener("DOMContentLoaded", (event) => {
console.log("DOM fully loaded and parsed");
});It fires when the initial HTML document's DOM has been loaded and parsed. However, this does NOT wait for stylesheets, images, fonts and subframes to finish loading.
This means for taking accurate screenshots, it is not a good choice as there is a high chance that a screenshot may be taken before images and styles have had a chance to load and be applied to the web page.
Here's an example of using domcontentloaded:
const browser = await puppeteer.launch({
devtools: true,
defaultViewport: {
width: 1280,
height: 1024,
},
headless: false,
});
const page = await browser.newPage();
console.time("goto");
await page
.goto("https://twitter.com/jot", {
waitUntil: "domcontentloaded",
})
.catch((err) => console.log("error loading url", err));
console.timeEnd("goto");
await page.screenshot({ path: `twitter-domcontentloaded.png` });
await browser.close();When I ran this,the goto step took 764ms until the domcontentloaded event fired. The resulting screenshot is:

As you can see, the page is just showing the twitter logo in the centre of the screen, so this screenshot has been taken too early.
If we change the url to bbc.co.uk, we get the following screenshot:
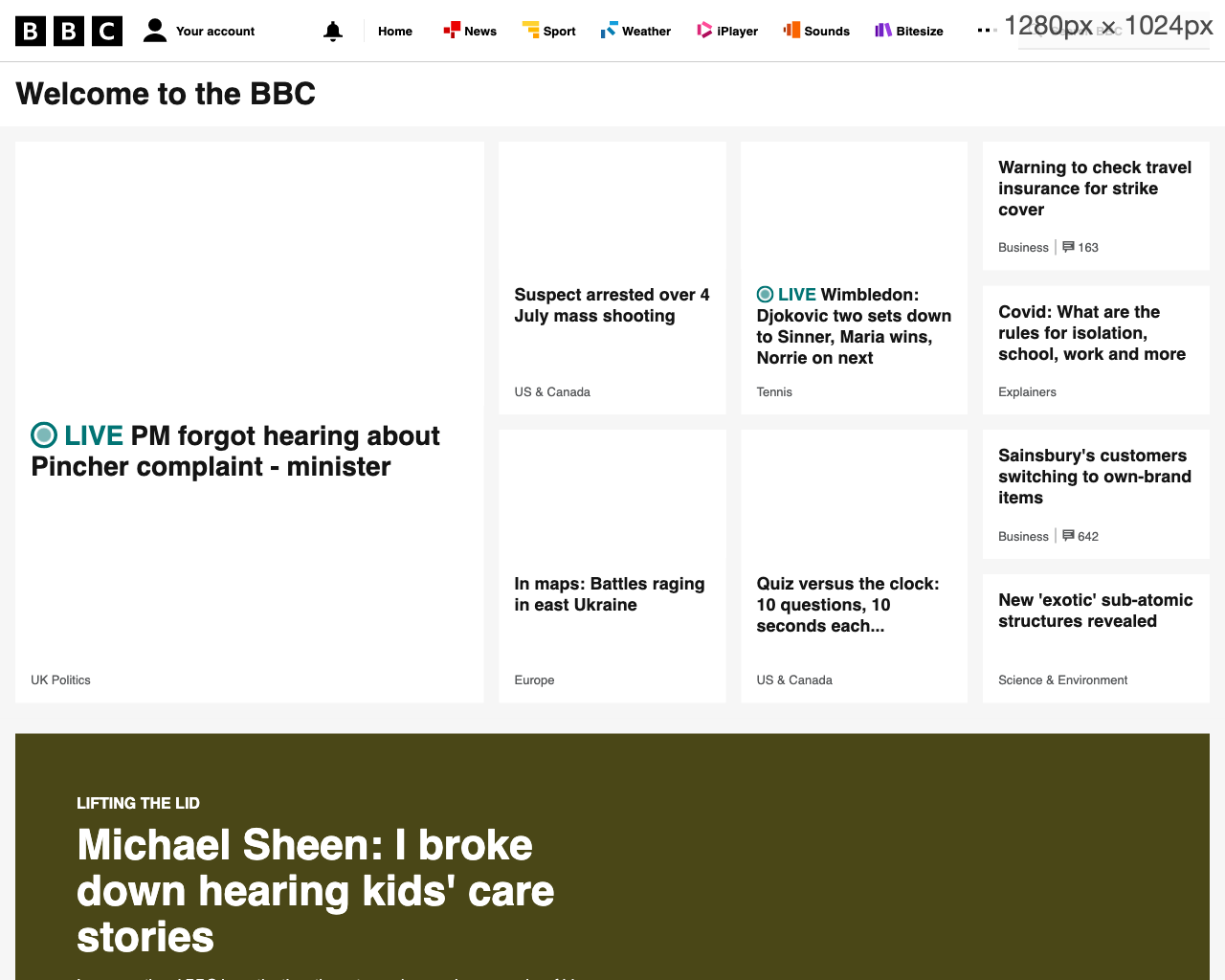
This took 1.9s for the goto step to complete. In this screenshot of bbc.co.uk, we have a bit more of the DOM structure, and the styles have (suprisingly) been applied, however because domcontentloaded doesn't wait for other resources, the images have yet to load in this screenshot.
waitUntil: load
The load option fires when the whole page has loaded, including all dependent resources such as stylesheets, fonts and images.
It is equivalent to waiting for the load event on the window:
window.addEventListener("load", (event) => {
console.log("page is fully loaded");
});Let's change the example above to wait for the load event:
...
console.time("goto");
await page
.goto("https://twitter.com/jot", {
waitUntil: "load",
})
.catch((err) => console.log("error loading url", err));
console.timeEnd("goto");
await page.screenshot({path: `twitter-load.png` });
...This time, the goto step took 716ms, and the screenshot is identical:

As you can see, there is little change in the screenshot of twitter. Why is that?
It is most likely because the initial HTML that twitter sends does not include direct links to resources such as images, therefore the page load event just fires when the initial DOM has been parsed, which for twitter is really early on.
Twitter relies on the browser to parse and load a big javascript bundle. Only once the browser has finished evaluating the javascript and constructed the DOM, will then be directed to load further resources such as images, videos, stylesheets and webfonts.
Let us try bbc.co.uk again, and compare with the previous screenshot:
bbc.co.uk - domcontentloaded, 1.9s, images not loaded
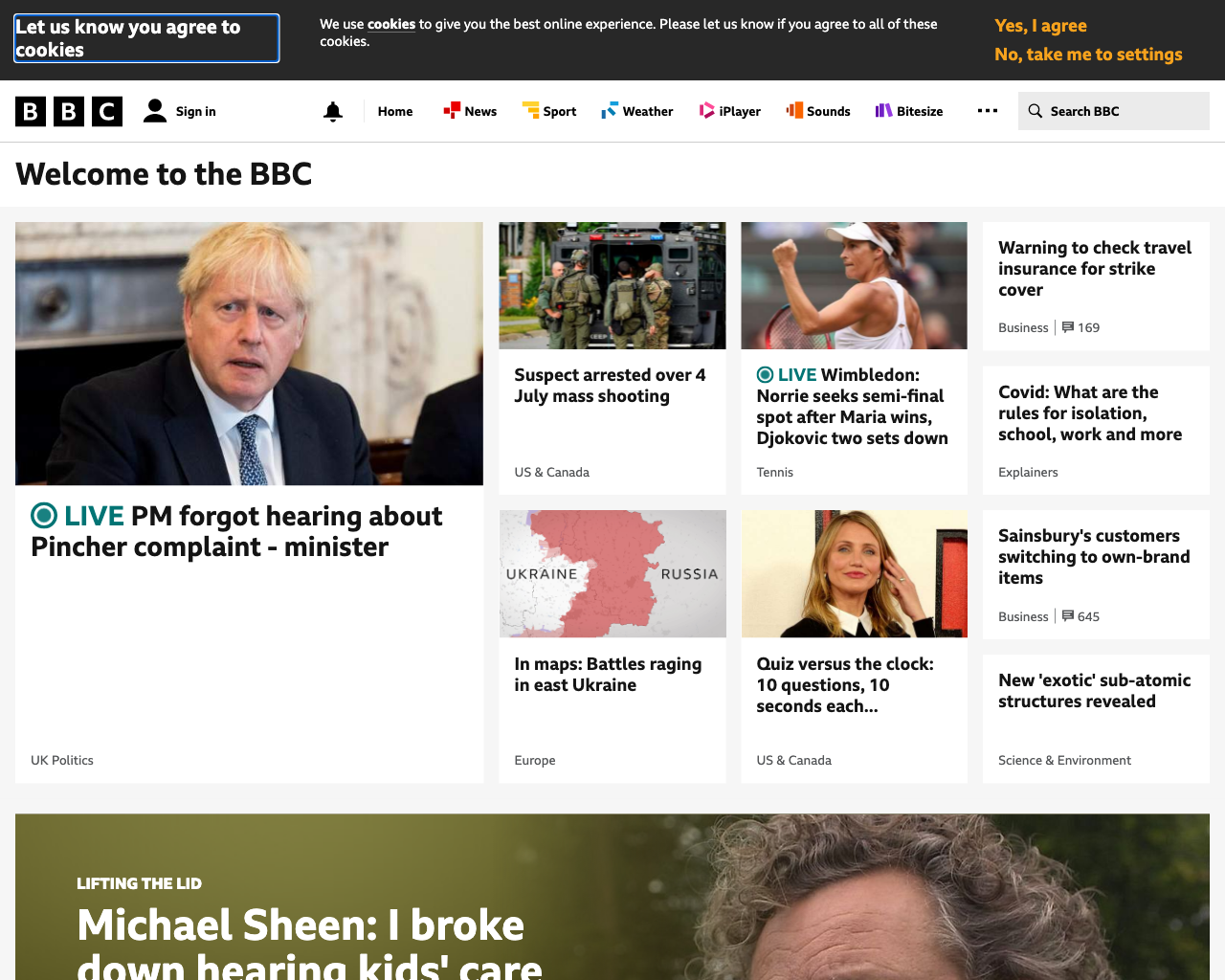
load, 4.36s, images are loaded This time, the load event took 4.36s to fire and has meant that bbc's images have
all loaded. It also gave enough time for the site to render a cookie banner at the
top - great 😝
When load is not enough
You might think that using the load event would be fine and the problem is solved, and you'd be almost correct - for traditional websites the load event should be fine.
However, there are of course a large and growing percentage of websites that act differently.
These sites will continue to load parts or even the majority of the page, after the load event has fired.
The classic example is a single page app (or SPA for short) that returns a slim initial HTML document, and relies on the browser to download and parse a load of javascript and then construct the completed webapp. This is exactly how the twitter.com site works.
The initial body HTML for a single page app might be something as bare bones as:
<html>
<head>
<!-- various meta tags for SEO... -->
<title>Some title</title>
<!-- link to the main javascript bundle -->
<script
type="text/javascript"
src="some/path/to/main_javascript_bundle.js"
></script>
<style>
// styles for loading page template and loading spinner here...
#loading-spinner {
...;
}
</style>
</head>
<body>
<!-- once the javascript bundle has been downloaded, parsed and executed, the
completed site will attach itself to the #root dom element or similar. -->
<div id="root"></div>
<div id="loading-spinner"></div>
</body>
</html>This kind of lean initial document will cause the domcontentloaded and load events to fire very quickly.
In this case, a screenshot taken after those events fire, will result in a screenshot of an incomplete loading page with images, styles and even part of the final DOM still not in place. Just like we have seen with our twitter.com screenshots above.
This is where Puppeteers networkidle0 and networkidle2 can help.
waitUntil: networkidle0
When passing networkidle0, puppeteer will wait for there to be no network activity for at least 500ms.
This works well for SPAs that load resources after parsing a javascript bundle or with fetch requests.
When you first open a tweet on twitter.com, you can see the initial HTML document is tiny, and nothing like what the completed page looks like. You can see the initial HTML payload that gets sent from twitters server by viewing the page source in your browser.
You'll also notice that there is a loading spinner which takes quite a while to load additional content such as the actual tweet content.
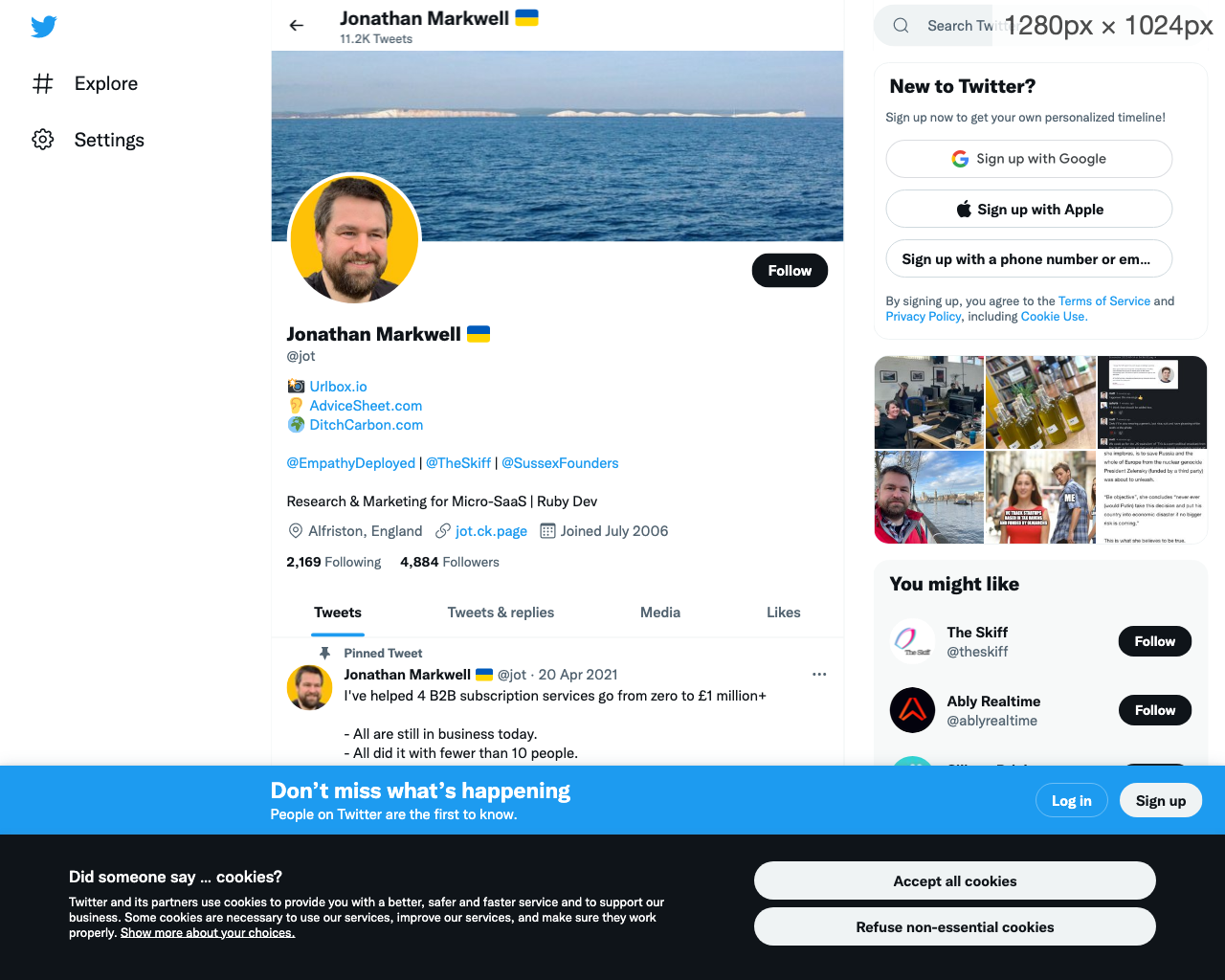
Using networkidle0 on a site like twitter, will ensure that the screenshot is not taken until there is at least 500ms between any network requests. This should usually be good enough to allow all of the additional requests that twitter.com makes to complete before the event fires.
Let's change the example to wait until networkidle0 is fired:
...
console.time("goto");
await page
.goto("https://twitter.com/jot", {
waitUntil: "networkidle0",
})
.catch((err) => console.log("error loading url", err));
console.timeEnd("goto");
await page.screenshot({path: `twitter-networkidle0.png` });
...This time the goto step took 5.94s, and the screenshot looks like:
waitUntil: networkidle2
There is a chance that when using networkidle0 the event may never fire, because the site is always busy with some network activity. This could be long polling, or high frequency analytics tracking over websockets.
Another option is to use networkidle2, which allows no more than 2 active network requests for a window of 500ms.
This means that if a site is constantly pinging a server, but there are only 2 network requests active, the event will still fire.
Switching to networkidle2 for our twitter example doesn't yield any difference in the screenshot, and the time taken was 5.99s, however for some websites, it may reduce the amount of time needed to wait compared with networkidle0.

using Page.waitForNetworkIdle() to customise the idle timeout
Whilst networkidle0 and networkidle2 options are hard coded to buffer for 500ms between network requests, Puppeteer does have an option that allows you
to wait a custom amount of time for the network to be idle.
The Page.waitForNetworkIdle() method takes an idleTime option which allows you to specify a custom amount of time in milliseconds to wait for the network to be completely idle. This is
equivalent to setting networkidle0 but instead of waiting for 500ms, we can now tell puppeteer to wait for idleTime ms.
Since we need to make a separate call in order to use the waitForNetworkIdle method, we can set the initial waitUntil option of the page.goto to domcontentloaded, which should fire early, and then wait for network idle.
We use Promise.all to wait for both promises to resolve. :
await Promise.all([
page.goto("https://twitter.com/jot", {
waitUntil: "domcontentloaded",
}),
page.waitForNetworkIdle({ idleTime: 250 }),
]);use Page.waitForSelector() to wait for an element to be present, visible, absent or hidden
In some cases the previous options that rely on browser load events, and network activity will not work reliably.
For example, if you're trying to take a screenshot of a chart in a dashboard that takes a while to load data from the server (looking at you powerbi 😜), and then render it to the screen, a good option is to wait for a specific element that you know will be present in the DOM when the chart or page has fully loaded.
We can use Page.waitForSelector() like so, the {visible: true} option tells Puppeteer to wait for the element to be present in the DOM and not to have display:none or visibility:hidden css properties:
await Promise.all([
page.goto("https://twitter.com/jot", {
waitUntil: "domcontentloaded",
}),
page.waitForSelector(".page-loaded", { visible: true }),
]);We can also use this method to wait for an element to NOT be in the DOM, or to be hidden, by passing the { hidden: true } option. This could be useful if you know that you don't want to take a screenshot
until a certain element has left the DOM, for example waiting for a loading spinner to leave:
await Promise.all([
page.goto("https://twitter.com/jot", {
waitUntil: "domcontentloaded",
}),
page.waitForSelector(".loading-spinner", { hidden: true }),
]);Note that if your selector refers to multiple instances, for example, you want to wait for all loading spinners to be hidden in the DOM, then this method will only wait for the first element that it finds.
Also, if your element happens to be inside a sub frame of the page, and not in the main frame, Puppeteer won't find it, and most likely the call will end up timing out.
Urlbox's equivalent options do take these edge cases into account and will check in all iframes of the page for the selector, and also use document.querySelectorAll(selector) to query for the selector.
Puppeteers waitForXPath is a similar function that takes an XPath expression instead of a css selector, to identify an element.
Wait for frame / request / response
If you know that a certain website will have fully loaded once it receives a specific request or response, you can use Puppeteers, waitForRequest and waitForResponse methods.
These take either a url, or a function that takes an HTTP Request (or HTTP Response) and allows you to run your own predicate function on it, such as matching a regex.
await Promise.all([
page.goto("https://example.com", {
waitUntil: "domcontentloaded",
}),
page.waitForRequest("https://example.com/some/resource"),
]);example using waitForResponse with predicate function:
await Promise.all([
page.goto("https://example.com", {
waitUntil: "domcontentloaded",
}),
page.waitForResponse(
(response) =>
response.url().match(/example.com/) && response.text().includes("<html>")
),
]);Similarly, if a page contains many frames, and you only care when a certain frame has loaded, you can use the page.waitForFrame function which also takes either a url, or a predicate function with Frame as argument:
await Promise.all([
page.goto("https://example.com", {
waitUntil: "domcontentloaded",
}),
page.waitForFrame(
(frame) => frame.url().match(/example.com/) || frame.name() == "myframe"
),
]);Wait for a function
You can use page.waitForFunction() to run a function in the context of the website that
will determine whether or not the page has loaded.
await page.waitForFunction("renderingCompleted === true");Using MutationObserver to wait for the DOM to settle
The trouble with a lot of the waitFor* functions are that they require specific knowledge about the site upfront.
For example, you either need to identify an element on the page to wait for, or a particular request.
What happens if you want a reliable way to know when any site has finished loading? Unfortunately, such a function does not exist that guarantees a site is loaded, for all sites on the web. If it did exist, then Puppeteer, and all other browsers, would provide it.
However, one strategy that can give a good indication, without needing to know anything specific about the site, is to listen to changes to the DOM and, similarly to the networkidle events,
fire an event when the DOM has been 'idle' for a certain amount of time.
To do this, we can make use of puppeteers page.evaluate function, to run code inside the page context, and gain access to the DOM's native MutationObserver. According to MDN, the MutationObserver provides the ability to watch for changes being made to the DOM tree. Sounds useful for our use case.
When you setup a MutationObserver, you pass it a root element and a callback function, where any changes to the root elements subtree, such as insertion or deletion of DOM elements, or changing of attributes, will fire the observers callback function.
We cannot assume that document.body will exist on every website, so we can use document.body || document.documentElement as the root element.
Within the mutation observers callback function, we can use a debounced function that will only resolve our promise once it has not been called for a certain amount of time.
Here is an example waitForDOMToSettle function that could be waited on alongside page.goto and other wait functions. The method will wait for the DOM to be idle for 1 second and timeout after 30 seconds.
const waitForDOMToSettle = (page, timeoutMs = 30000, debounceMs = 1000) =>
page.evaluate(
(timeoutMs, debounceMs) => {
let debounce = (func, ms = 1000) => {
let timeout;
return (...args) => {
console.log("in debounce, clearing timeout again");
clearTimeout(timeout);
timeout = setTimeout(() => {
func.apply(this, args);
}, ms);
};
};
return new Promise((resolve, reject) => {
let mainTimeout = setTimeout(() => {
observer.disconnect();
reject(new Error("Timed out whilst waiting for DOM to settle"));
}, timeoutMs);
let debouncedResolve = debounce(async () => {
observer.disconnect();
clearTimeout(mainTimeout);
resolve();
}, debounceMs);
const observer = new MutationObserver(() => {
debouncedResolve();
});
const config = {
attributes: true,
childList: true,
subtree: true,
};
observer.observe(document.body, config);
});
},
timeoutMs,
debounceMs
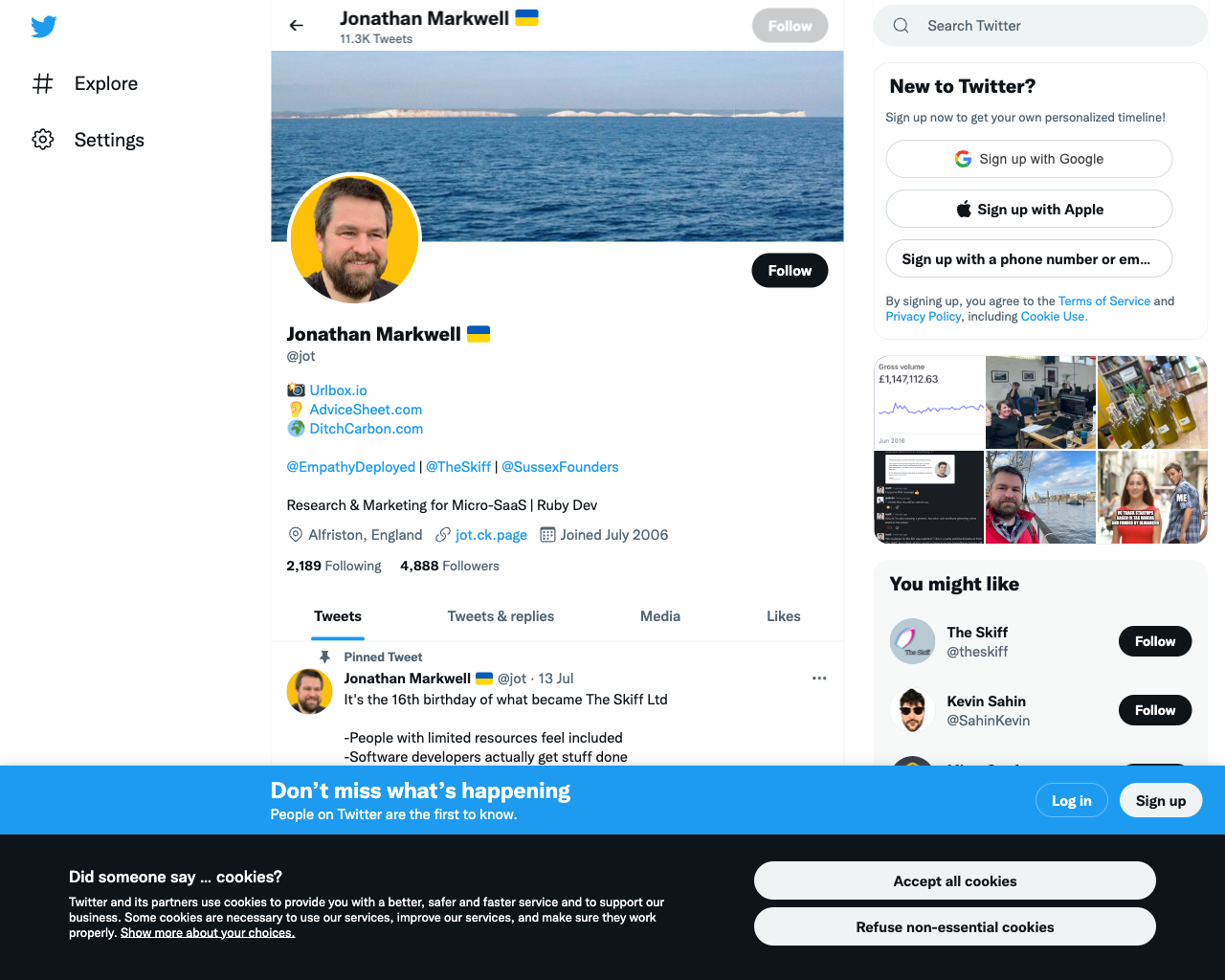
);Let's try it out with the twitter.com url from before. Note that we don't use Promise.all here to run both functions in parallel, because for the waitForDOMToSettle function to work properly, we need to have established that the DOM has loaded, hence we run this function after page.goto has resolved with the waitUntil option set to domcontentloaded:
...
console.time("goto");
await page.goto("https://twitter.com/jot", {
waitUntil: "domcontentloaded",
});
await waitForDOMToSettle(page);
console.timeEnd("goto");
...Here, the goto step took 9.4seconds, and the resulting screenshot looks like:
Conclusion
Waiting for a page to load in order to get a clean screenshot is a lot more tricky than it first appears, depending on how that page is implemented.
We've gone through all of the features that puppeteer provides that allow us to wait for a page to load:
We can wait for certain events to fire, such as load and domcontentloaded.
We can use puppeteer to wait for certain DOM elements to be hidden or visible.
We also explored puppeteers methods that wait for the network to be idle for certain lengths of time before continuing. These can be useful for single page apps that are built with frameworks such as angular, react and vue.
Finally, we wrote a custom function that waits for updates to the DOM to settle, which could be as close as we can come to making a generic page load function that works across all websites.
