
If you're looking for a reliable and fast way to convert webpages to PDFs, then you've come to the right place.
In this article, we'll cover:
-
why convert webpages to PDFs in bulk
-
a list of different tools and services you can use
-
how to convert webpage to PDF in various web browsers
- our recommendation of the best webpage to PDF converter APIs.
Converting a Webpage to PDF Use Cases
People are always looking for ways to share, print, and view content in various formats, such as PDF files.
This article highlights some of the best ways and tools you can use to convert a webpage to PDF automatically.
Many people recognize the value of a PDF file. It's a versatile format that can be viewed, printed, and shared from a variety of devices, including computers and mobile phones.
PDF files make it easy to share content that has been created or published online. For example, if you have a blog or website where you post articles, you might want to be able to convert the articles into a PDF file that your readers can download (otherwise known as a lead magnet).
This way, you can use an existing piece of content to increase your email list.
In other situations, PDFs may be used for internal purposes to distribute documents within an organization.
Other use cases include:
-
Generating PDF invoices from HTML
-
Generating PDF catalogs of influencer or PR campaigns
-
Submit PDFs of webpages for compliance reviews
- Generate PDFs on demand.
There are many different ways to convert a webpage to a PDF document programmatically. These techniques take different approaches and require varying levels of programming expertise.
While the concept of creating a PDF from HTML is simple, the details involved are often confusing for web developers and business owners alike.
To make matters worse, solutions to this problem are constantly changing as browsers evolve. Read on to learn some of the available options for converting an HTML page to PDF, from DIY examples to APIs that can be used with a single line of code.
A PDF has to look professional
Try manually printing a webpage with the built-in Chrome functionality, and you’ll quickly realize that generating a PDF from a webpage is more complicated than it seems.
Of course, you can implement your microservice or even use a headless browser to generate that PDF, but that doesn’t really solve the problem. Think of all the extra elements that’ll be part of the file, like the ads on your website, the cookie banners, privacy disclaimers, and the list goes on and on.
If you're trying to generate screenshots at scale, you want to make sure your go-to webpage to PDF tool can handle these problems by default.
There are some great screenshot tools, but just a handful would let you easily create high-quality PDF files. Even if you can convert your site into a PDF, when you look at the final result, there is still plenty of work to do before sharing these files with anyone.
Here are some things that you have to pay attention to in case you want to go the DIY way:
-
The quality of the screenshots themselves
-
Ads, cookies banners, and other obscuring elements
-
That your site looks the same in any browser - you want users to have the experience exactly as they see it in their browser
-
Constant updates are required because browsers are constantly updating and may often break compatibility with existing services
-
Font rendering is critical - if you choose to embed fonts and have them appropriately rendered in your PDFs, then they need to look good in every browser as well
- Running out of memory because too many PDFs are being processed at the same time.
Building your own webpage to PDF microservice
Chances are you read this article because you've realized creating PDFs from webpages is a more challenging task than initially expected. You’ve gone through Stackoverflow and already asked your friends, but you haven’t entirely found your answer yet. Some people are leaning towards Puppeteer, which is Google's library for creating PDF files from HTML content. Others are suggesting Playwright, a popular library that does essentially the same thing as Puppeteer but has a much gentler learning curve.
As it turns out, many business owners have built their own webpage-to-PDF microservice in-house because they don't need to generate thousands of PDFs at once. These small businesses usually have a handful of PDFs they need to generate per month, so they can build this functionality themselves and save money on third-party services.
So which one should you use? Well, to make an educated decision, let's take a look at how Puppeteer and Playwright compare to each other:
Puppeteer
Puppeteer is by far one of the most popular libraries for PDF generation. It's an easy-to-use open-source library, plus you can find examples of how to work with it just about anywhere. The downside is that it requires an out-of-process server.
Puppeteer does all its PDF generation asynchronously, sending the generated PDF back to your application upon completion. This makes Puppeteer less than ideal for applications that need to generate PDFs as part of their core functionality.
Puppeteer isn't a great choice if you want more than just PDFs—it's best when you're using it only as a bonus feature on top of your core functionality, like an eCommerce site that generates invoices or receipts automatically.
Playwright
With Playwright, you can generate PDFs from any website, whether the single page of a manual or a multi-page document.
It helps you extract text from PDFs by typing a few lines of code. You will be able to save yourself hours of work and have a lot more fun by using this tool to automate your processing of PDFs.
While using Playwright, you also have many options in terms of tweaking the PDFs, such as changing the orientation, width, height, or format.
However, as mentioned before, running your own microservice becomes a chore once you scale. The biggest impediment is running into bugs and the microservice getting extremely expensive.
The solution is often outsourcing your website to PDF service to an API.
Webpage to PDF APIs
Screenshots are a standard tool in software development and testing, and as such, there is a growing number of companies offering screenshot or webpage to PDF APIs.
These are much like the APIs you use to access other web services, such as Twitter or Facebook, but instead of providing data on a website's content, they provide a pixel-perfect image or PDF of the page.
Finding a screenshot API is a lot like shopping for a hosting provider. The important thing to look for is not just the features included with the service but whether or not those features are exposed via a robust API.
With that in mind, it's essential to choose an API provider who will be able to evolve and grow with your needs.
Urlbox
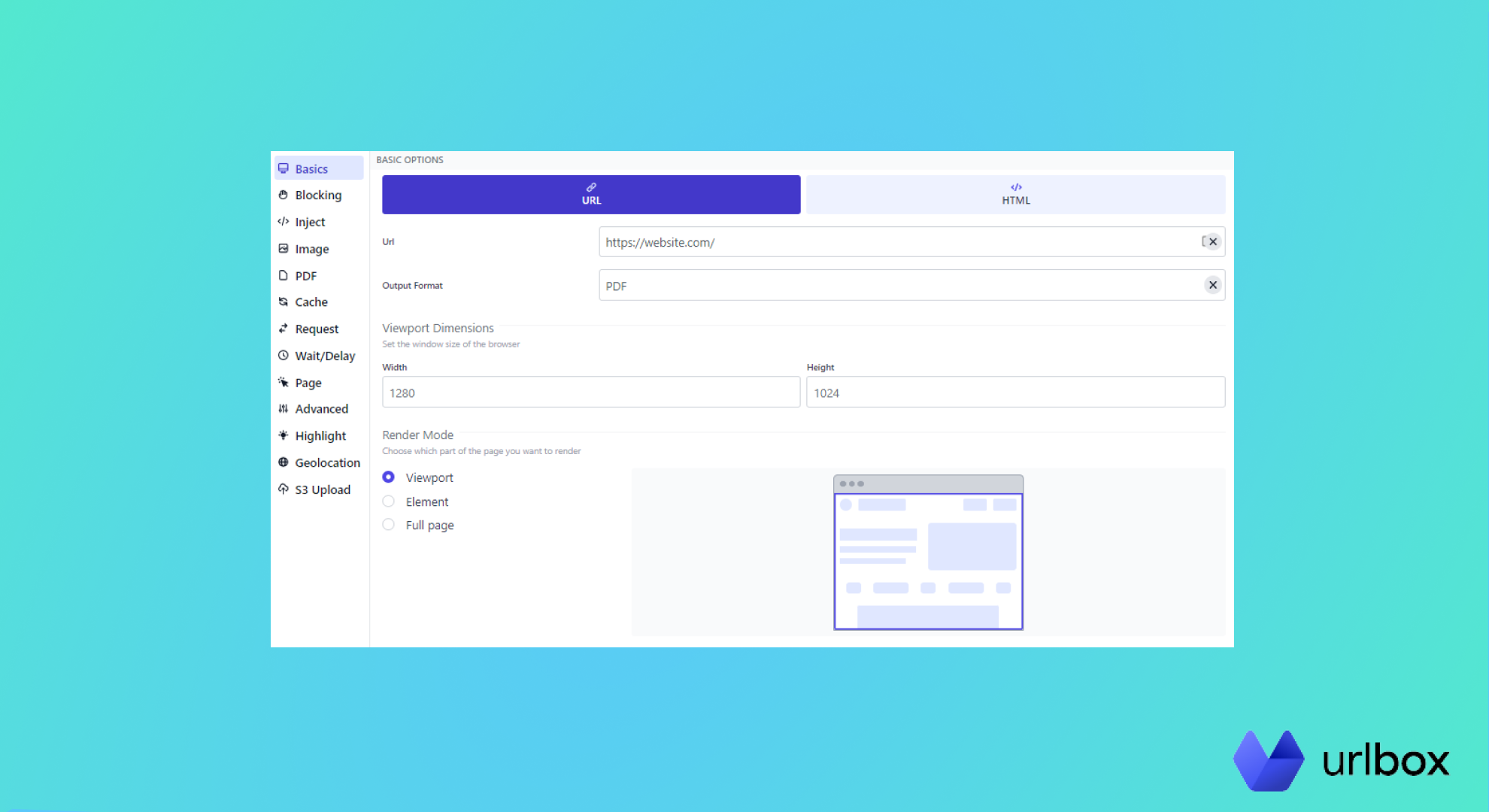
Urlbox is a simple and reliable API that can convert any webpage into a pdf on demand. Urlbox offers excellent support for converting web pages into PDFs, with a large variety of options such as:
-
set the PDF page size, width, height, and margin
-
print background images in the PDF or not
-
control how Urlbox caches your PDFs
-
configure the browser before navigating the URL
- set cookies on request when loading a URL.
Other webpage to PDF APIs
1.Api2Pdf
Api2Pdf is an API that allows you to generate and merge PDFs from HTML, URLs, images, or office documents.
It was updated a year ago, and you can use it with Node.js, Go, Kotlin, and various other programming languages you might be using in your stack.
With cloudlayer.io, you can generate PDFs by making a GET request to convert URLs to images or PDFs. The API was updated over eight months ago.
3.Pdflayer
Pdflayer is a lesser-known API that converts HTML files (and URLs) to PDF files. It comes with a series of layout adjustment options, authentication and security, design and branding tweaks, and other functionalities.
Use a reliable and fast webpage to PDF API
Urlbox is a service designed to make it easier for people to take screenshots or PDFs of webpages and use the assets without worrying about scaling, hosting, or dealing with the edge cases that come with generating PDFs of various websites.
We handle the scaling, the hosting of the screenshot images and PDFs, and we solve a lot of the edge cases that people will run into, such as blocking ads and cookie banners automatically.
Try it out for yourself here!
